 Home-theater-designers
Home-theater-designers
Как аналитик данных, вы часто сталкиваетесь с необходимостью объединения нескольких наборов данных. Вам нужно будет сделать это, чтобы завершить анализ и сделать вывод для вашего бизнеса/заинтересованных сторон.
Часто бывает сложно представить данные, когда они хранятся в разных таблицах. В таких обстоятельствах соединения доказывают свою ценность, независимо от языка программирования, над которым вы работаете.
СДЕЛАТЬ ВИДЕО ДНЯ
Соединения Python похожи на соединения SQL: они объединяют наборы данных, сопоставляя их строки в общем индексе.
Создайте два кадра данных для справки
Чтобы следовать примерам в этом руководстве, вы можете создать два образца DataFrames. Используйте следующий код для создания первого кадра данных, который содержит идентификатор, имя и фамилию.
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)На первом этапе импортируйте панды библиотека. Затем вы можете использовать переменную, а , чтобы сохранить результат конструктора DataFrame. Передайте конструктору словарь, содержащий необходимые значения.
Наконец, отобразите содержимое значения DataFrame с помощью функции печати, чтобы убедиться, что все выглядит так, как вы ожидаете.
Точно так же вы можете создать еще один DataFrame, б , который содержит значения идентификатора и зарплаты.
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)Вы можете проверить вывод в консоли или IDE. Он должен подтвердить содержимое ваших DataFrames:
Чем объединения отличаются от функции слияния в Python?
Библиотека pandas — одна из основных библиотек, которую вы можете использовать для управления DataFrames. Поскольку кадры данных содержат несколько наборов данных, в Python доступны различные функции для их объединения.
Python предлагает функции соединения и слияния, среди многих других, которые вы можете использовать для объединения фреймов данных. Между этими двумя функциями существует огромная разница, о которой вы должны помнить, прежде чем использовать любую из них.
Функция соединения объединяет два кадра данных на основе значений их индексов. функция слияния объединяет DataFrames на основе значений индекса и столбцов.
Что нужно знать о объединениях в Python?
Прежде чем обсуждать доступные типы соединений, обратите внимание на несколько важных моментов:
- Соединения SQL — одна из самых основных функций. и очень похожи на соединения Python.
- Чтобы присоединиться к DataFrames, вы можете использовать pandas.DataFrame.join() метод.
- Соединение по умолчанию выполняет левое соединение, тогда как функция слияния выполняет внутреннее соединение.
Синтаксис соединения Python по умолчанию выглядит следующим образом:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)Вызовите метод соединения для первого DataFrame и передайте второй DataFrame в качестве его первого параметра, Другой . Остальные аргументы:
- на , который называет индекс для объединения, если их несколько.
- как , который определяет тип соединения, включая внутреннее, внешнее, левое и правое.
- лсуффикс , который определяет левую строку суффикса имени вашего столбца.
- рсуффикс , который определяет правильную строку суффикса имени вашего столбца.
- Сортировать , который является логическим значением, указывающим, следует ли сортировать полученный DataFrame.
Научитесь использовать различные типы соединений в Python
В Python есть несколько вариантов соединения, которые вы можете использовать в зависимости от необходимости. Вот типы соединения:
1. Левое соединение
Левое соединение сохраняет значения первого DataFrame нетронутыми, в то же время внося соответствующие значения из второго. Например, если вы хотите ввести совпадающие значения из б , вы можете определить его следующим образом:
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)Когда запрос выполняется, выходные данные содержат следующие ссылки на столбцы:
- ID_left
- Fимя
- Lname
- ID_right
- Зарплата
Это объединение извлекает первые три столбца из первого кадра данных и последние два столбца из второго кадра данных. Он использовал лсуффикс а также рсуффикс значения, чтобы переименовать столбцы идентификаторов из обоих наборов данных, гарантируя уникальность результирующих имен полей.
Результат выглядит следующим образом:

2. Правильное соединение
Правильное соединение сохраняет значения второго DataFrame нетронутыми, в то же время внося соответствующие значения из первой таблицы. Например, если вы хотите ввести совпадающие значения из а , вы можете определить его следующим образом:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)Результат выглядит следующим образом:
как подключить мой телефон к компьютеру
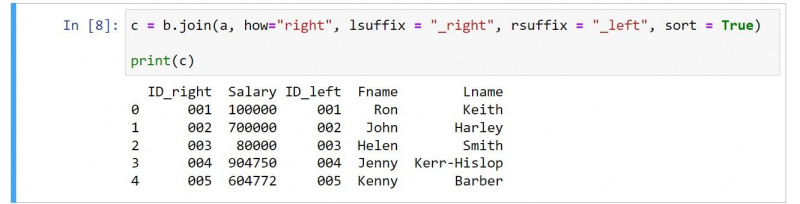
Если вы просмотрите код, то увидите несколько очевидных изменений. Например, результат включает столбцы второго кадра данных перед столбцами первого кадра данных.
Вы должны использовать значение Правильно для как аргумент для указания правильного соединения. Также обратите внимание, как вы можете переключать лсуффикс а также рсуффикс значения, отражающие характер правильного соединения.
В ваших обычных соединениях вы можете чаще использовать левое, внутреннее и внешнее соединения по сравнению с правым соединением. Однако использование полностью зависит от ваших требований к данным.
3. Внутреннее соединение
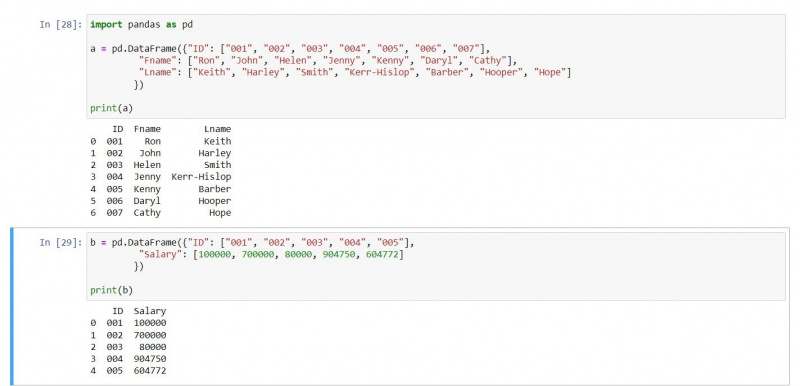
Внутреннее соединение доставляет совпадающие записи из обоих DataFrames. Поскольку соединения используют порядковые номера для сопоставления строк, внутреннее соединение возвращает только совпадающие строки. Для этой иллюстрации давайте используем следующие два кадра данных:
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)Результат выглядит следующим образом:
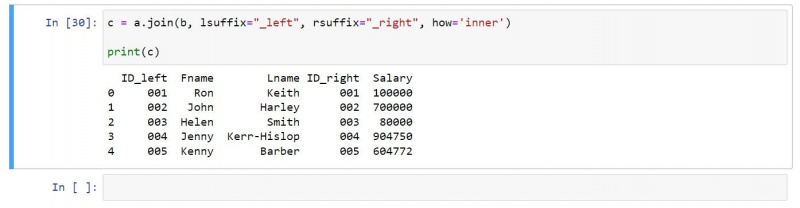
Вы можете использовать внутреннее соединение следующим образом:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)Результирующий вывод содержит только те строки, которые существуют в обоих входных кадрах данных:
4. Внешнее соединение
Внешнее соединение возвращает все значения из обоих DataFrames. Для строк без совпадающих значений он создает нулевое значение в отдельных ячейках.
Используя тот же DataFrame, что и выше, вот код для внешнего соединения:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)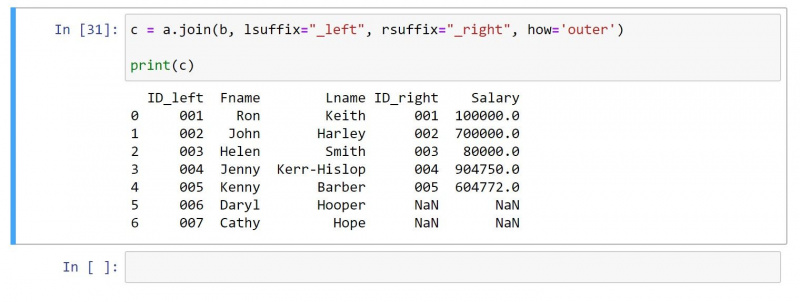
Использование объединений в Python
Соединения, как и аналогичные им функции слияния и объединения, предлагают намного больше, чем просто функциональность соединения. Учитывая его ряд опций и функций, вы можете выбрать опции, отвечающие вашим требованиям.
Вы можете относительно легко сортировать полученные наборы данных, с функцией объединения или без нее, с помощью гибких опций, которые предлагает Python.